Organizing, Subsetting and Processing Data
(access to this page in GitHub)
Now that you’ve successfully downloaded the GRACE and GLDAS data, you will need to read in and process the data to get groundwater anamoly estimates. Both datasets have raw data contained in .nc or .nc4 files. These are files for storing multi-dimensional data–in our case, the key dimensions we are interested in are latittude and longitude (geography) and time. We can use the xarray package to read in these data.
Reading in GRACE and GLDAS Data
Both datasets have similar processes for loading in the data which are outlined in detail below. However, the first step for processing both datasets is to filter to your region of interest. This is important because it makes processing times for each step much quicker. As such, our first step in processing will be loading in a shapefile and filtering to the region of interest before loading in GRACE and GLDAS and merging them with other datasets
Subsetting The Data
For most use cases, it will make the most sense to load in a shapefile and use this file to narrow down your region. This will allow your analysis to focus on your area of interest as precisely as possible and improve the efficiency of your code. If you don’t have a shapefile or know your region of interest, you can pick any 4 latitude/longitude points and use them to draw a rectangle around a region of the world you are interested in. You can also skip this step, but note it will make the code take much longer to run.
For our analysis here, we will use a shapefile that focuses on the Colorado River Basin.
What is a Shapefile?
A shapefile is a file that stores geometric location and attribute information of geographical features in a nontopological way. Shapefiles represent geographical features by points, lines, or polygons (geographical areas) (ArcGIS). It is one of the simpler ways to store and work with geographic data. Many shapefiles are publicly available for download by government agencies, researchers, or practitioners. Below is an example of what a shapefile looks like in tabular form and how you can go from that to a map.
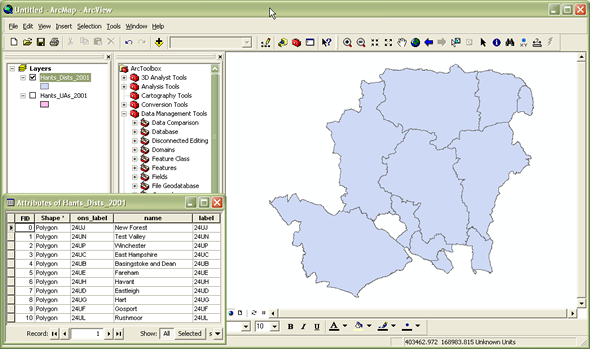 Source: ReStore
Source: ReStore
Applying This Method to the CRB
Below, we use this method to use a shapefile of the Colorado River Basin for analysis. You can download the shape file for the Colorado River Basin from ArcGIS hub here. After downloading the shapefiles, remember to move them to the data/shapefiles folder to run the code to read the shapefile. A visual of this is shown below:
To work with shapefiles, we will use the geopandas package, a spatial analysis package built on top of pandas. We will begin by loading in this package and reading in the shapefile. Next, we will load in plotting functions from matplotlib and map the shapefile.
# import necessary packages and libraries
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
import numpy as pd
import xarray as xr
import os
from datetime import datetime
basin_shapefile = gpd.read_file("data/shapefiles/Colorado_River_Basin_Hydrological_Boundaries_with_Areas_served_by_Colorado_River.shp")
# Select only the upper and lower basin
basin_shapefile = basin_shapefile[-2:]
# Plot of entire Colorado River Basin
plt.style.use('ggplot')
plt.figure(figsize=[10,10])
basin_shapefile.plot()
plt.title("Colorado River Basin")
plt.grid(which="minor")
plt.minorticks_on()
plt.show()
A simple way to start narrowing down to the area within the Colorado River Basin is to construct a rectangle around the region and only read in and process rows within that rectangle:
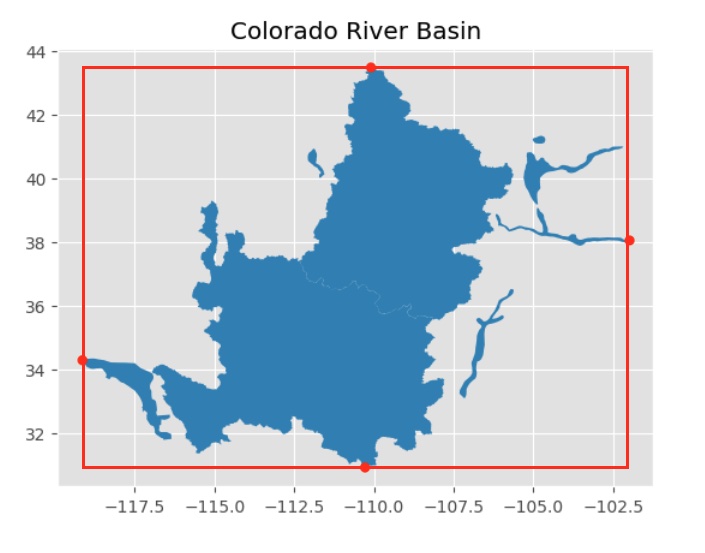
As you can see from the image above, a substantial amount of geography that is not within the CRB is still in the rectange. We will use spatial processes to eliminate those from our dataset later in the process. For now though, focusing on this rectangle will greatly speed up reading and applying other transformations to the data.
The code to do this is provided below.
# Code to filter to shapefile
# extract a dataframe of the coordinates from the shapefile
coords = basin_shapefile.get_coordinates()
# find the maximum and minimum lat/longs, corresponding to the red points on the figure above
lon_min = min(coords['x'])
lon_max = max(coords['x'])
lat_min = min(coords['y'])
lat_max = max(coords['y'])
GRACE
The GRACE MASCON data is contained in 1 .nc file and contains global land MASCON GRACE data. We start by using xarray to read in the data.
# Need to change this to relative path later
grace = xr.open_dataset("data/GRACE_MASCON/data/TELLUS_GRAC-GRFO_MASCON_CRI_GRID_RL06.1_V3/GRCTellus.JPL.200204_202304.GLO.RL06.1M.MSCNv03CRI.nc")
# print out grace data. Note our interest variable lwe_thickness is measured in centimeters
grace
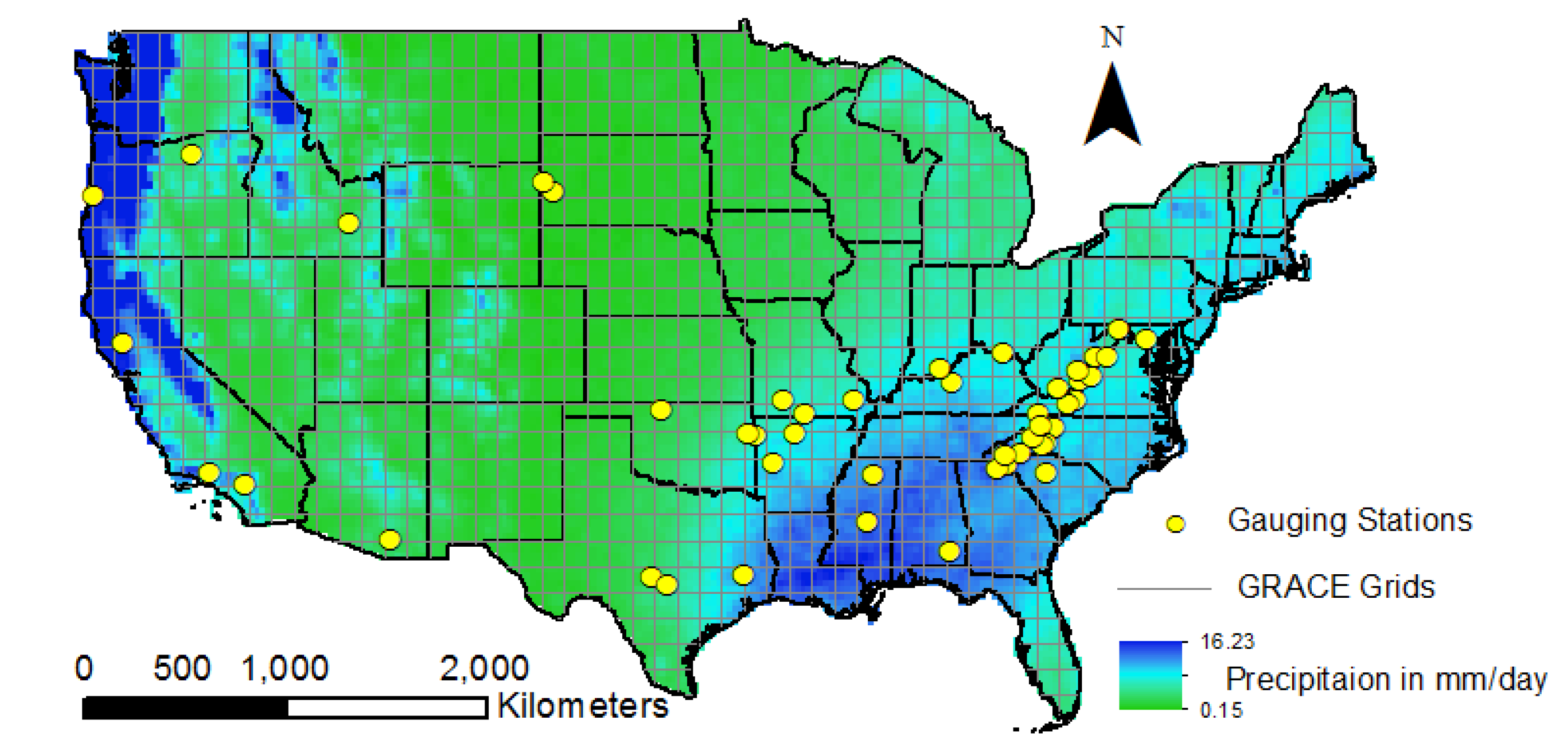
The first thing you will note is that the dataset has several dimensions: lon, lat, time, and bounds. This is because the GRACE data come at the pixel-level for each year. In our sitution, a pixel is the smallest geographic unit of analysis. Because collecting and processing GRACE satellite data is technical and compuationally expensive, GRACE measurements are given as .5-degree by .5-degree squares. The pixels cover the entire Earth’s surface and each have a GRACE measurement monthly from 2002-present. A visual of this is shown below, where each square in the GRID correponds to a pixel (Sharma, Patnaik, Biswal, Reager, 2020). Note that the yellow dots are gauging stations for comparison.
First, since the data is an xarray dataset, we can do some processing to transform the dataset into a standard tabular, pandas dataframe. For efficiency, we can also only select the variables we need, and for use with other datasets, we will transform the longitude points from a [0,360] range to a [-180,180] range.
An important point to note is that when we change our data into a tabular format, each latitude and longitude combination will be the center of a pixel and will uniquely identify each pixel. Thus, it is important to understand that the associated value is not representative of this exact point but rather the entire pixel that the point is a center of. Though not necessary for our analysis, if you wanted to get the coordinates of each of the four corners, you would just have to add and subtract the pixel length divided by 2 to each latitude and longitude value.
def convert_longitude(lon):
if lon >= 180:
return lon - 360
else:
return lon
# transforming to dataframe and selecting relevant vars
grace_df = grace[['lon','lat','time','lwe_thickness','uncertainty','scale_factor']].to_dataframe()
grace_df.reset_index(inplace=True)
grace_df.reset_index(drop=True)
grace_df = grace_df.rename(columns={'lwe_thickness': 'lwe_thickness_cm', 'uncertainty': 'uncertainty_cm'})
# dropping duplicates, since there will be a duplicate for each lat/lon combo because of the bounds
grace_df = grace_df.drop_duplicates()
#subsetting to rectangle containing the Colorado River Basin
grace_df['lon'] = grace_df['lon'].apply(convert_longitude)
grace_df = grace_df[(grace_df.lon> lon_min) & (grace_df.lon < lon_max)]
grace_df = grace_df[(grace_df.lat> lat_min) & (grace_df.lat < lat_max)]
grace_df
The last step in processing GRACE data is to multiply lwe_thickness at each pixel by a scale factor and convert the units. The scale factors are intended to restore much of the energy that is removed due the sampling and post-processing of GRACE observations. More information about the scaling factors can be found here. Moreover, please note that NASA states users should multiply the data by the scaling coefficient, so it is imperative not to skip this step.
The original terrestrial water storage is measured in centimeters, we convert the unit to kimoleter cubed by:
- convert the terrestrial water storage to kilometer
- multiplying each data point by the surface area of each pixel measured in kilometer squared to get terrestrial water storage in kilometer cubed
In the following code, we also converted the unit of uncertainty for your convenience in case you want to incorporate uncertainty in your calculation. More information on how to incorporate uncertainty is documented in the Understanding Uncertainty file. Note: the scale factor does not have a unit nor change with time, so no handling of it needs to be attended to
grace_df.sort_values(by='time', inplace=True)
# Compute surface area for pixel with dimension 0.5 x 0.5 degree. Note the area of pixel changes with latitude. 6,371 is Earth's radius in kilometer
EARTH_RADIUS_KM = 6371
grace_df['surface_area_km2_0.5'] = EARTH_RADIUS_KM * np.radians(.5) * EARTH_RADIUS_KM * np.radians(.5) * np.cos(np.radians(grace_df['lat']))
# Converting units from cm to km3
CM_TO_KM_RATIO = 1e-5
grace_df["lwe_thickness_km3"] = grace_df["lwe_thickness_cm"] * grace_df['scale_factor'] * CM_TO_KM_RATIO * grace_df['surface_area_km2_0.5']
grace_df['uncertainty_km3'] = grace_df["uncertainty_cm"] * CM_TO_KM_RATIO * grace_df['surface_area_km2_0.5']
grace_df
GLDAS Data
Next, we will read in the GLDAS data which provides us with information on snow pack and soil moisture. These data are similarly in a multidimensional data format which can be read in using xarray. However, the data come in individual files that require being read in and combined into one dataset. The code below does this.
# Read in one file of the GLDAS data as a demonstration
# Note the interested variables "SWE_inst" and "RootMoist_inst" are measured in kilogram per square meter (kg/m2)
xr.open_dataset("/data/GLDAS/NOAH_monthly_L4/GLDAS_NOAH025_M.A200001.021.nc4")
### import GLDAS data, filter to CRB, combine into one dataframe
gldas_path = "data/GLDAS/NOAH_monthly_L4/"
gldas_df = pd.DataFrame()
#Iterating through files in path
for filename in os.listdir(gldas_path):
if filename.endswith(".nc4"):
#Reading in data as xarray then converting to DataFrame
xd = xr.open_dataset(gldas_path+str(filename))
xd_df = xd.to_dataframe()
xd_df.reset_index(inplace=True)
xd_df = xd_df[(xd_df.lon> lon_min) & (xd_df.lon < lon_max)]
xd_df = xd_df[(xd_df.lat> lat_min) & (xd_df.lat < lat_max)]
#Extracting only needed columns
df_slice = xd_df[["time", "lon", "lat", "SWE_inst", "RootMoist_inst"]]
df_slice = df_slice.drop_duplicates()
gldas_df = pd.concat([gldas_df, df_slice], axis=0)
gldas_df = gldas_df.rename(columns={'SWE_inst': 'SWE_inst_kg/m2', 'RootMoist_inst': 'RootMoist_inst_kg/m2'})
In the following code, we are changing the units of Soil Moisture and Snow Water Equivalent to kilometer cubed. The two variables are originally measured in kg/m2.
We convert the unit to kimoleter cubed by:
- multiply each data point by 1,000,000 to convert the data point in kg/km2
- multiply each data point by the surface area of each pixel measured in kilometer squared to get the two variables measured in kilograms
- At standard temperature and pressure, water has density of 1 kg/Liter. So 1 kg water = 1 Liter = 1e-12 kilometer cubed. We multiply the data by (1e-12) to get the data in kilometer cubed
# Compute surface area for pixel with dimension 0.25 x 0.25 degree.
gldas_df['surface_area_km2_0.25'] = EARTH_RADIUS_KM * np.radians(.25) * EARTH_RADIUS_KM * np.radians(.25) * np.cos(np.radians(gldas_df['lat']))
# Converting units from kg/m2 to km3
KG_PER_M2_TO_KG_PER_KM2_RATIO = 1e6
KG_TO_KM3_RATIO = 1e-12
gldas_df['RootMoist_inst_km3'] = gldas_df['RootMoist_inst_kg/m2'] * KG_PER_M2_TO_KG_PER_KM2_RATIO * gldas_df['surface_area_km2_0.25'] * KG_TO_KM3_RATIO
gldas_df['SWE_inst_km3'] = gldas_df['SWE_inst_kg/m2'] * KG_PER_M2_TO_KG_PER_KM2_RATIO * gldas_df['surface_area_km2_0.25'] * KG_TO_KM3_RATIO
gldas_df
Focusing on the Basin
Returning to the GRACE data, we saw earlier that though the data is filtered down to a rectangle containing the Colorado River Basin, there are still areas that are not contained in the rectangle. We can use geoprocessing techniques from geopandas to keep points in GRACE that only intersect the shape file.
# Create a GeoDataFrame directly from grace_df
grace_gdf = gpd.GeoDataFrame(grace_df,
crs='epsg:4326',
geometry=gpd.points_from_xy(grace_df['lon'], grace_df['lat']))
# Ensure the CRS for basin_shapefile is set correctly
basin_shapefile.crs = "EPSG:4326"
# Use sjoin to find points that intersect with the shapefile
intersected = gpd.sjoin(grace_gdf, basin_shapefile, how="inner", predicate="intersects")
# Select the columns we are interested in
grace_df = intersected[['lon', 'lat', 'time', 'lwe_thickness_cm', 'uncertainty_cm', 'scale_factor', 'surface_area_km2_0.5','lwe_thickness_km3', 'uncertainty_km3']]
Upsampling GRACE
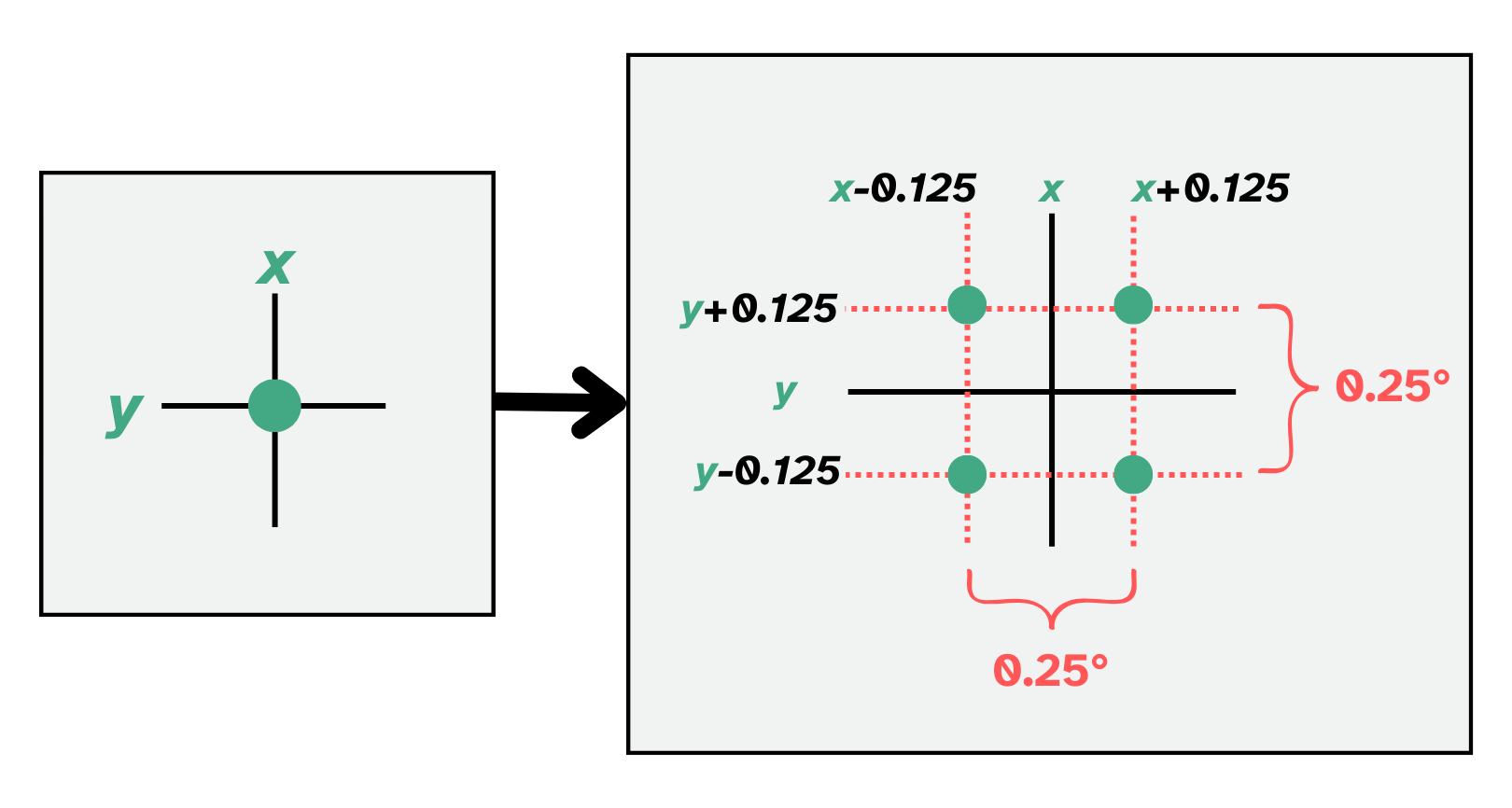
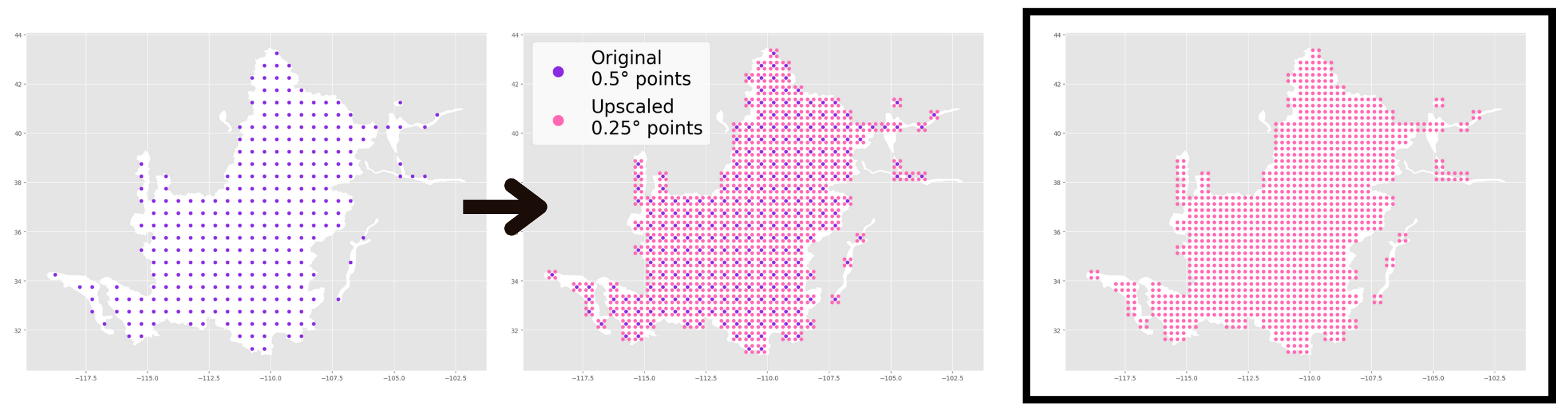
One key consideration for combining GRACE and GLDAS data is that pixels in GRACE data are .5°x.5° while GLDAS data has .25°x.25° pixels. One way to handle this without loss of data is to “upscale” GRACE data to make it mergable with GLDAS. That is, transform the GRACE data pixels from .5°x.5° to .25°x.25°. That is, we transform the GRACE data pixels from a granularity of .5°x.5° to one of .25°x.25°. This process yields a four points for each original point.
One way we can do this is to “upsample” GRACE data. This is shown visually below:
After upsampling, you are left witha final product of evenly-spaced, non-overlapping $.25°x.25°$ pixels (shown below, far right panel).
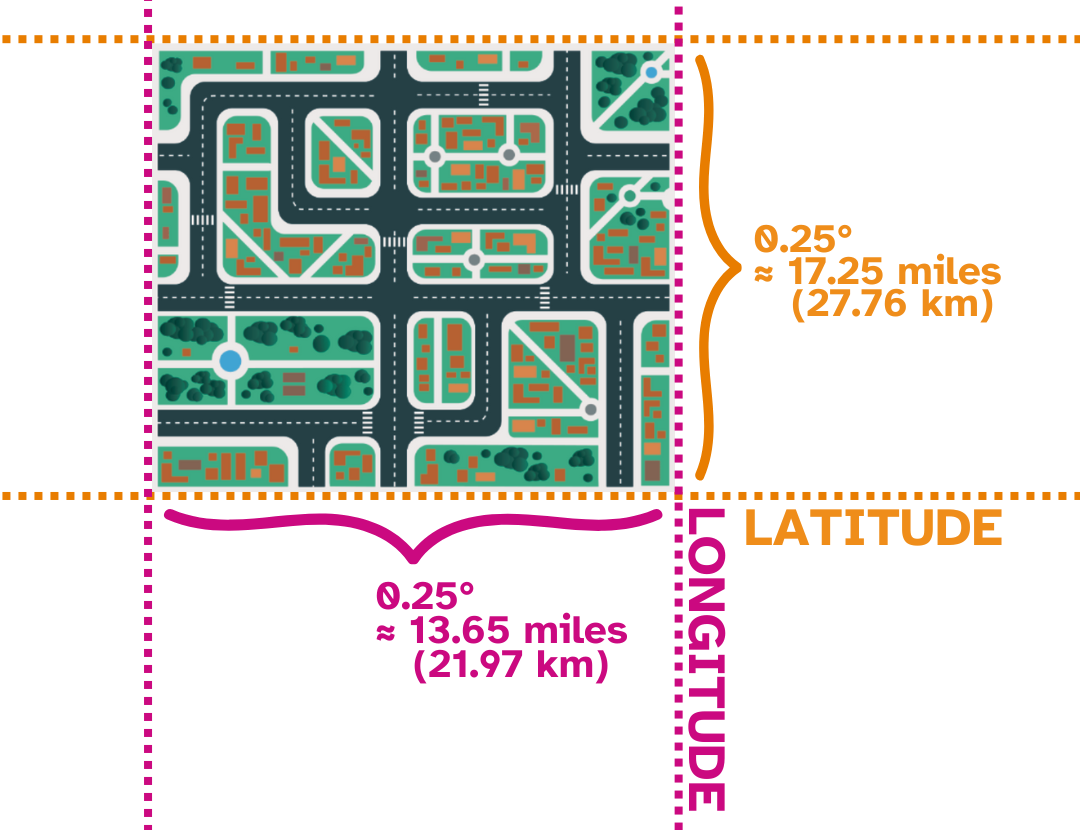
Each “pixel” thus represents a chunk of land approximately 235.46 miles squared ($\approx$ 378.94 kilometers squared). A visualization of an individual pixel is shown below.
# Helper function to generate the upsampled GRACE data
def upsample_point(row):
# For the row of GRACE dataframe inputted in the function, we first store the time, lon, lat, lwe_thickness, and uncertainty value
t = row['time']
x = row['lon']
y = row['lat']
lwe = row['lwe_thickness_km3']
uncertainty = row['uncertainty_km3']
# Create upscaled longitude values (by creating a distance of 0.125 on each side of the
# original longitude (x), you obtain a total length of 0.25 around each original point)
xx = [round(x-0.125,3), round(x+0.125,3)]
# Create upscaled latitude values (by creating a distance of 0.125 on each side of the
# 0riginal latitude (y), you obtain a total length of 0.25 around each original point)
yy = [round(y-0.125,3), round(y+0.125,3)]
# Returning a list of upsampled points for the row inputted, notice the lwe_thickness and the uncertainty value stay the same
return [
{"time": t, "lon": xx[0], "lat": yy[0], "lwe_thickness_km3": lwe, 'uncertainty_km3': uncertainty},
{"time": t, "lon": xx[0], "lat": yy[1], "lwe_thickness_km3": lwe, 'uncertainty_km3': uncertainty},
{"time": t, "lon": xx[1], "lat": yy[0], "lwe_thickness_km3": lwe, 'uncertainty_km3': uncertainty},
{"time": t, "lon": xx[1], "lat": yy[1], "lwe_thickness_km3": lwe, 'uncertainty_km3': uncertainty}
]
# Loop over each row in the GRACE dataframe and perform the helper function to generate a list of upsampled points
upsampled_points = [record for _, row in grace_df.iterrows() for record in upsample_point(row)]
# Convert the list of upsampled points into a DataFrame
upsampled_grace_df = pd.DataFrame(upsampled_points)
Edge Pixels
The edges of the basin often do not completely intersect with a pixel. For example, in the figure below, each square on the graph is a 5°x.5° square. As you can see, within the center of the basin, there is perfect overlap between several pixels and the basin. However, when you get to the outer edges of the basin, you can see that there is not perfect overlap with a pixel. The basin only covers part of a pixel around the edges.
For our analysis, we only include a pixel in calculating groundwater anamolies if the center of the pixel is contained within the basin. This will generally include pixels that have a majority of their area within the basin and exclude pixels that do not. Additionally, since the Colorado River Basin is so large, the effect of edge cases on our calculations will be small. However, if you plan to analyze the region within a smaller basin, one strategy to account for this is to use an area weighting average of the pixel with the basin. This will allow you to weight your values by the area that intersects both the pixel and the basin.
# Plot of entire Colorado River Basin
plt.style.use('ggplot')
plt.figure(figsize=[10,10])
basin_shapefile.plot(alpha=.3, edgecolors='black')
plt.title("Colorado River Basin")
plt.grid(which="minor")
plt.minorticks_on()
plt.show()
Merging the Datasets
Now that GRACE and GLDAS are in standardized, tabular formats, we can merge these datasets together to combine all the variables of interest and calculate groundwater estimates. Note that since the GRACE data is already filtered to the area of interest, we can simply perform a left join to merge GLDAS with GRACE data.
# Standardize times in both datasets and do a left join
upsampled_grace_df['time'] = pd.to_datetime(upsampled_grace_df["time"].astype(str).str.slice(0, 7), format='%Y-%m')
gldas_df['time'] = pd.to_datetime(gldas_df["time"].astype(str).str.slice(0, 7), format='%Y-%m')
grace_gldas_df = upsampled_grace_df.merge(gldas_df, on=["time", "lat", "lon"], how="left")
Calculating Anamolies
In order to compute groundwater anamolies, you need to compute the deviation from the mean for each measurement:
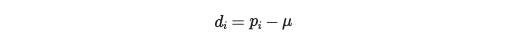
where d_i is the deviation from the mean for obervation i, p_i is the measurement for observation i, and μ is the average over the specified time period.
In order to calculate μ, you take the average for each water category over a specified time period. Here, we use the time period from 2004-2009, following NASA and recent literature, which is shown in code below. Note that the code is easily modifiable if you would like to focus on a different time period.
grace_gldas_df
# Filter the dataframe to include only the required dates to calculate average
TIME_PERIOD_START = '2004-01-01'
TIME_PERIOD_END = '2009-12-31'
mask = (grace_gldas_df['time'] >= TIME_PERIOD_START) & (grace_gldas_df['time'] <= TIME_PERIOD_END)
filtered_df = grace_gldas_df.loc[mask]
# Group by lat and lon and calculate average storage for the specified date range
average_df = filtered_df.groupby(['lat','lon']).agg({'SWE_inst_km3':'mean', 'RootMoist_inst_km3':'mean'}).reset_index()
average_df = average_df.rename(columns={'SWE_inst_km3':'SWE_mean_km3', 'RootMoist_inst_km3':'RootMoist_mean_km3'})
grace_gldas_df = grace_gldas_df.merge(average_df, on=['lat','lon'], how='left')
# Compute the anomaly for soil moisture and snow water equivalent
grace_gldas_df['SWE_anomaly_km3'] = grace_gldas_df['SWE_inst_km3'] - grace_gldas_df['SWE_mean_km3']
grace_gldas_df['RM_anomaly_km3'] = grace_gldas_df['RootMoist_inst_km3'] - grace_gldas_df['RootMoist_mean_km3']
If you want to compute the mean of another time period, you would need to:
- multiply each GRACE data point by the mean of GRACE for that pixel from the time period 2004 to 2009
- calculate the mean of GRACE for the time period you want for every pixel
- subtract each GRACE observation by its mean for the new pixel
Step 2 and 3 are similar to the code chunk above where we calculated the anomaly for Snow Water Equivalent and Soil Moisture